
So now you have downloaded at least one dataset, and in previous part you also set up the parltrack no-db console. Now what? how do you know what is in the dataset? For this to answer Parltrack publishes the "schema"s of the datasets on the dumps page. In the table there is a column with a link to the schema for each of the datasets. Some datasets have a v1 version and a v2. You want to use mostly v2 unless you download a dataset that is from before the v2 rewrite of Parltrack.
Let's have a look at part of the ep_meps schema:
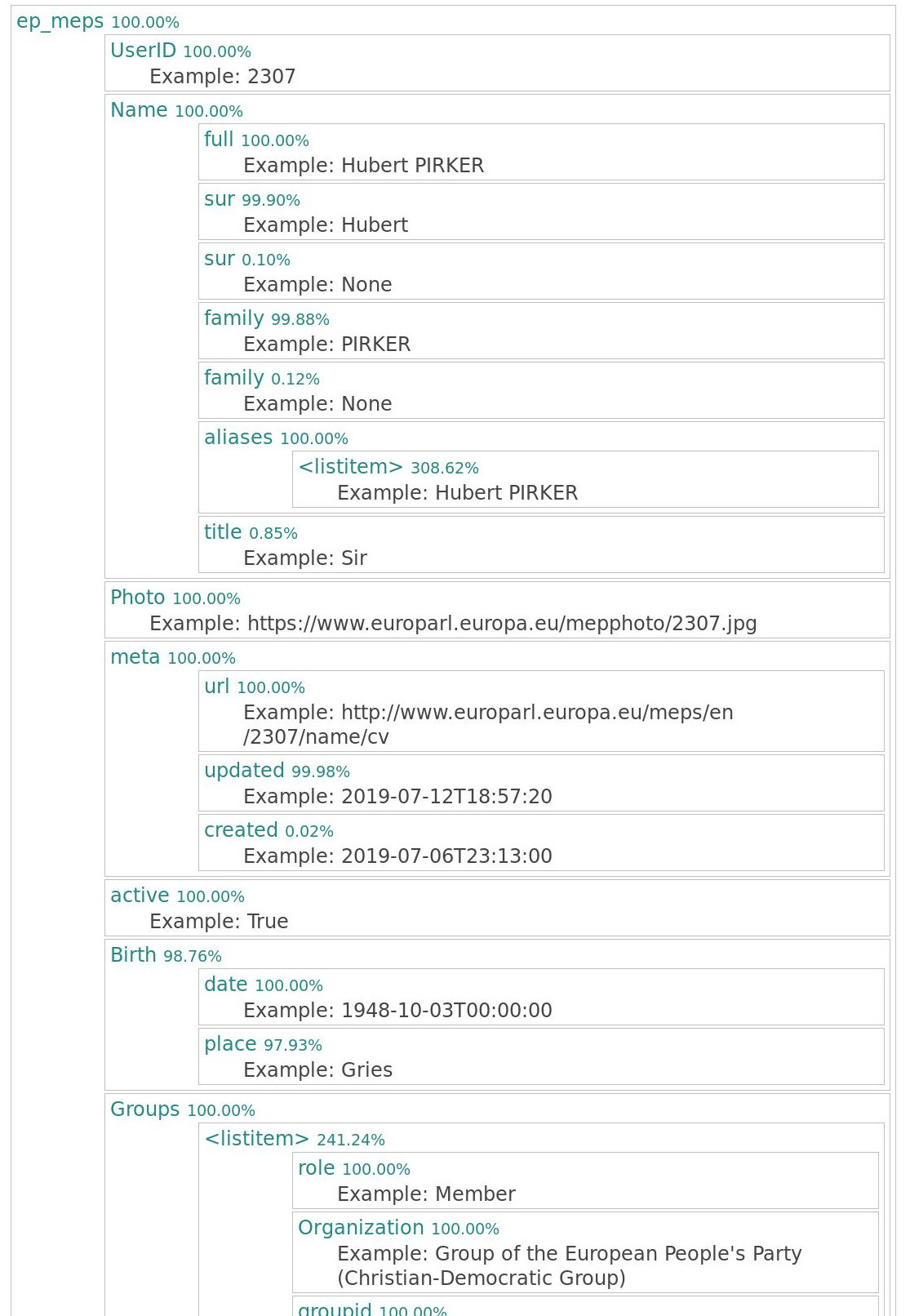
You can see, that every MEP we have in this dataset has a name. No big surprise here, but what is surpising that 0.1% do not have a surname, and 0.12% do not have a family name!
All of the MEPs do have aliases - which are basically their names in all kind of orders: surname-familyname, familyname-surname, and combinations in case there's titles, and other oddities, like previous names of the same persion, which might have changed due to gender-change or change of marital status.
You can also see that the list of aliases has on average 308% content, that is a bit more than three different aliases in this list.
You can also see that not all of the MEPs publish either their birthdate or their birthplace.
For homework, try to come up with a "query" that lists all MEPs that have no:
- Surname
- Familyname
- Birthday
- Birthplace
happy hacking
"Data in parltrack is not tabular, only subsets of it would fit into cells of spreadsheets, the schemas give an clear view on what to expect from the datasets" observes Hanni L. Eckthor, intern for storage cells&rows.